Distributed Gradient Boosted Decision Tree on GPU
Alex Xiao (axiao@andrew.cmu.edu)
Rui Peng (ruip@andrew.cmu.edu)
Summary
We are going to implement an optimized distributed implementation of training gradient boosted decision trees. We plan to use OpenMPI for communication between nodes, and CUDA to parallelize each individual node’s training on GPU. If time allows, we also will attempt to implement a hybrid implementation of parallel decision tree learning that makes use of both CPUs and GPUs.
Background
Decision trees are a common model used in machine learning and data mining to approximate regression or classification functions. They take an input with a set of features and predict the corresponding label or value by using the nodes of the tree to split on the features. For example, below is an example of a decision tree used to assign a prediction score to whether or not a person likes computer games.
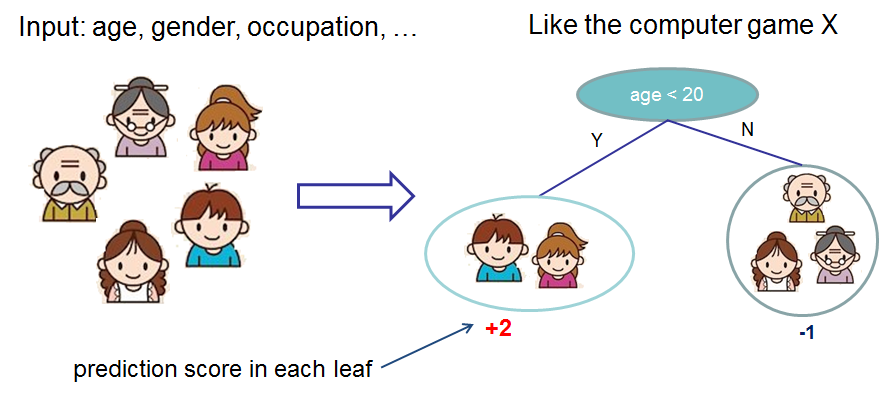
Ensemble learning is a machine learning technique to produce a prediction model from a collection of weak learners. The idea is that as long as the weak learner can do better than random guessing on average, then an ensemble of weak learners will have higher predictive performance than any individual weak learner. Gradient boosting achieves this by iteratively adding weak learners into the ensemble. On each iteration, after constructing a weak learner and adding it to the ensemble, the boosting algorithm will increase the weight of training data that the current model incorrectly predicts so that the next iteration will to try to “nudge” the constructed weak learner to address the current model’s weakness. Gradient boosting sets this up via an optimization problem where it uses gradient descent to minimize some loss function that captures the current ensemble’s performance when constructing new weak learners.
Although gradient boosting does not have opportunities for parallelism, being an inherently sequential process, parallelization opportunities exist in training an individual decision tree. Specifically, the main computation required when training a decision tree is to determine which feature the next node should split on. There are different algorithms for doing this, but this often requires comparing some kind of objective function across all the features, which should have good opportunities for parallelism since multiple threads can search for the best feature to split on simultaneously. Other potential areas of parallelism include processing different nodes in the tree or separate subsets of the data simultaneously. Our goal in this project will be to construct an algorithm that takes advantage of these axes of parllelism efficiently across different nodes in a cluster with GPUs to accelerate the training process. If possible, we would also like to run our algorithm efficiently on hybrid architectures and make use of both CPUs and GPUs.
The Challenge
We foresee four main challenges with distributed decision tree training.
- The shape of the decision tree is irregular and determined at runtime, making it difficult to statically partition the workload.
- The workload at each node of the decision tree can vary signficantly, causing further workload imbalance issues.
- Parallelizing across nodes in a cluster will likely require significant communication between machines as the decision on which feature to split on requires global information, yet each machine only has a local view of the data. Addressing this problem might require some kind of efficient encoding scheme or an algorithm that tries to maximize locality in each node.
- Most frameworks for decision tree learning support parallelism across CPU’s as their primary parallelism method. Only recently have these frameworks started to develop GPU implementations of decision tree training. The reasoning for this is that the algorithms they use do not translate well to GPU. To quote the creator of XGBoost, a widely used decision tree learning framework: “The execution pattern of decision tree training relies heavily on conditional branches and thus has high ratio of divergent execution, which makes the algorithm have less benefit from SPMD architecture”.
We plan to address these 4 challenges by utilizing techniques we have learned in 15-418 as well as utilizing ideas in current literature for parallel decision tree learning.
Resources
We plan to develop and test our code on latedays cluster because we need a good distributed environment that has GPUs.
We will start our implementation from scratch to have the fullest flexibility while we explore the problem. Should we ultimately decide to develop a CPU-GPU hybrid execution heterogeneous version, we might incorporate the StarPU task programming library in our code.
Goals and Deliverables
Baseline: a sequential CPU implementation with naive communication scheme of the algorithm on distributed setting.
We will measure the performance of various implementations as the speed up versus the baseline and report the speedup under different settings.
Plan to achieve:
- Significant speedup of parallel GPU implementation and efficient communication scheme over baseline version
Hope to achieve:
- Further speedup versus baseline version with an algorithm leveraging CPU+GPU hybrid execution architecture
Platform
C++/CUDA, Linux.
We choose C++/CUDA on Linux mainly because we are most familiar with the platform and it should be the best playground to make use of MPI and CUDA easily. Latedays also has both CPUs and GPUs, allowing us to attempt algorithms that run heterogenous architectures.
Schedule
April 10 - April 16
Research and brainstorm potential parallel algorithms, setup codebase, start working on distributed sequential version as a reference baseline.
April 17 - April 23
Complete distributed sequential version, measure accuracy and performance, start implementing parallel GPU version.
April 24 - April 30
Work on GPU version, measure accuracy and performance, optimize as necessary.
May 1 - May 7
If finished with GPU version, start implementation of CPU+GPU hybrid algorithm. Start performing measurements needed to analyze speedup and training accuracy.
May 8 - May 12
Wrap up, perform all measurements needed to analyze speedup and training accuracy, prepare presentation.